一致哈希是一种特殊的哈希算法。在使用一致哈希算法后。哈希表槽位数(大小)的改变平均仅仅须要对K/n个keyword又一次映射,当中K是keyword的数量,n是槽位数量。
然而在传统的哈希表中,加入或删除一个槽位的差点儿须要对全部keyword进行又一次映射。
一致哈希由MIT的Karger及其合作者提出,如今这一思想已经扩展到其他领域。在这篇1997年发表的学术论文中介绍了“一致哈希”怎样应用于用户易变的分布式Web服务中。哈希表中的每一个代表分布式系统中一个节点。在系统加入或删除节点仅仅须要移动K/n项。
分布式缓存设计核心点:在设计分布式cache系统的时候,我们须要让key的分布均衡。而且在添加cache server后,cache的迁移做到最少。
在使用n台缓存server时,一种经常使用的负载均衡方式是,对资源的请求使用hash(K) mod N来映射到某一台缓存server。当添加或降低一台缓存server时这种方式可能会改变全部资源相应的hash值。也就是全部的缓存都失效了,这会使得缓存server大量集中地向原始内容server更新缓存。因些须要一致哈希算法来避免这种问题。
一致哈希算法的主要思想:
将每一个缓存server与一个或多个哈希值域区间关联起来,当中区间边界通过计算缓存server相应的哈希值来决定。(定义区间的哈希函数不一定和计算缓存server哈希值的函数同样,可是两个函数的返回值的范围须要匹配。)假设一个缓存server被移除。则它会从相应的区间会被并入到邻近的区间,其他的缓存server不须要不论什么改变。实现:
一致哈希将每一个对象映射到圆环边上的一个点,系统再将可用的节点机器映射到圆环的不同位置。查找某个对象相应的机器时。须要用一致哈希算法计算得到对象相应圆环边上位置,沿着圆环顺时针查找直到遇到第一个节点机器。这台机器即为对象应该保存的位置。当加入一台机器到圆环边上某个点时。这个点的下一台机器须要将这个节点前相应的对象移动到新机器上。
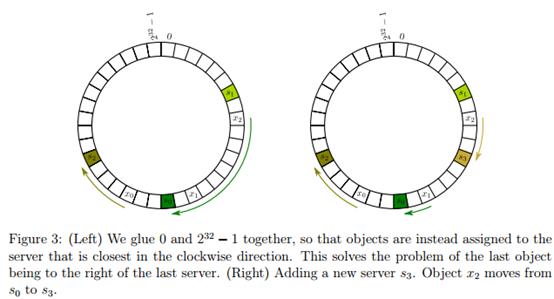
当删除一台节点机器时,这台机器上保存的全部对象都要移动到下一台机器。
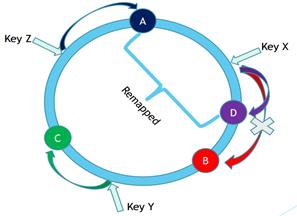
虚拟节点:
一致性哈希算法在服务节点太少时,easy由于节点分部不均匀而造成数据倾斜问题。例如以下:
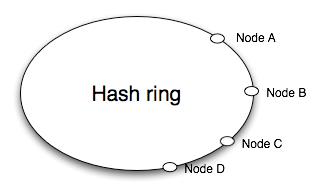
能够看到这里的A节点负载将非常重。
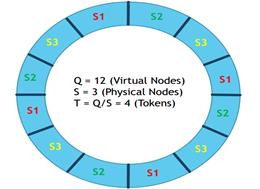
对此。我们把每台server分成v个虚拟节点,再把全部虚拟节点(n*v)随机分配到一致性哈希的圆环上,这样全部的用户从自己圆环上的位置顺时针往下取到第一个vnode就是自己所属节点。当此节点存在故障时,再顺时针取下一个作为替代节点。
參考: